Questions and answers about anything related to Helium Scraper
-
Christos
- Posts: 9
- Joined: Tue Apr 24, 2012 10:07 am
Post
by Christos » Thu Jun 21, 2012 5:27 am
Dear Juan,
The Software is very powerful and fast, however for noice users need some kind of detailed user manual with the descriptions, pictures or a small video introduing the eloberated meaning and use of various features mentioned below.
- Actions Actions List Extract To Variable
Actions Actions List Start Processes
The Rotate Proxy option
Use of Proxies
How to make use of start Process
How to make use of SQL Editior
Also detailed Example For Helium Scraper doing some advanced extraction, "
http://www.youtube.com/watch?v=eXizgGgo ... ature=plcp for this particualr Vedio "some information about kinds and actions trees would be useful in a presentation PPT or WordDoc.
-
Attachments
-
- Helium Scraper additional queries.png (90.03 KiB) Viewed 117119 times
-
hscraper
- Posts: 5
- Joined: Wed Jun 08, 2016 6:12 pm
Post
by hscraper » Wed Jun 08, 2016 6:49 pm
Sorry to post on an old post, but I second this. Incredible program, but much of the features/options are over my head. Tutorials with step-by-step and/or visuals would help immensely. Thanks!
PS: If someone can point me in the direction of a tutorial on 1) how to use proxies/what they do, and 2) the features available within HS related to proxies, that would be great.
-
webmaster
- Site Admin
- Posts: 521
- Joined: Mon Dec 06, 2010 8:39 am
-
Contact:
Post
by webmaster » Fri Jun 24, 2016 10:33 pm
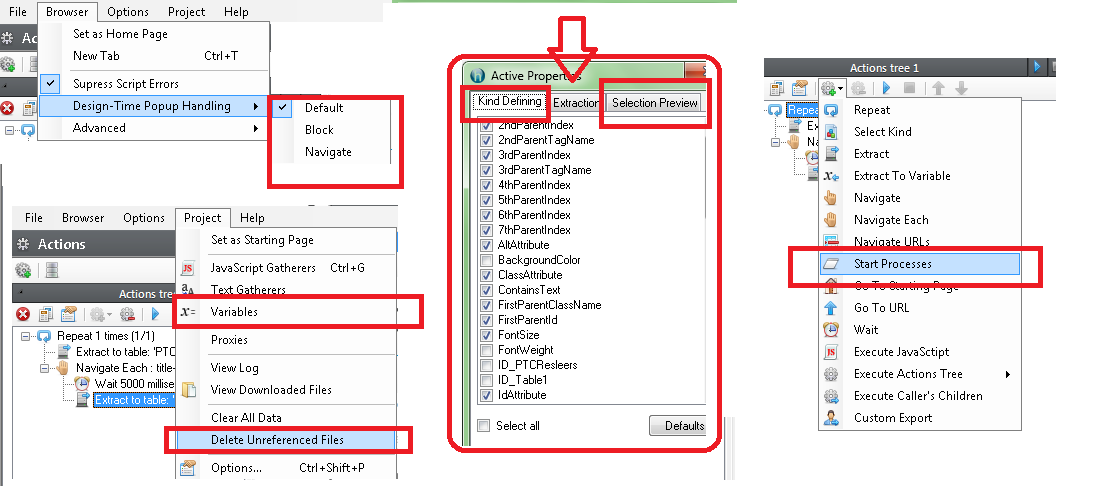
For now, here's some quick information about the some of these features:
- Browser -> Design-Time Popup Handling: Determines what to do with popup windows while you're manually browsing. Default will just show it on a new window (which will popup on IE), Block will block it, and Navigate will navigate to the popup's URL using Helium's browser. There's another option called Run-Time Popup Handling under Project -> Options which determines what to do with popup windows during extraction. Normally you'll use Navigate if you need data from them, or Block if they're just ads or stuff you don't need.
- Project -> Variables: There are just pairs of name/values that can be accessed during extraction from several places, such as the Extract to Variable action and some premades like Variable to Textbox and Data to Variables. Variables can also be extracted with an Extract action together with any other information from the page, by extracting the VAR_{YourVariableName} property (where {YourVariableName} is the name of the variable) from the BODY kind. And for coders, they can be accessed from JavaScript code using the SetVar and GetVar functions (see Actions -> Actions List -> Execute JavaScript -> Class List -> GlobalObject in the documentation),
- Delete Unreferenced Files: Deletes all the downloaded files that are not currently referenced by any output table (output tables are the ones that have a corresponding Extract action). So if, for instance, I have an Extract action that extracts to Table1, then I run it and download some files, then clear the table and download some new files, doing Delete Unreferenced Files will clear all the old files since they're not referenced by Table1 (which is an output table). Note that this will also delete any files that are referenced by tables that have no corresponding Extract action.
- Kind Defining, Extraction, Selection Preview: This determines where gatherers can be used:
- Kind Defining: These are the gatherers that are used when defining kinds (the ones that may appear under the kind name in the kinds panel). The more gatherers are checked, the more "picky" your kinds will be, meaning you'll need more sample elements, but they'll also be less likely to select the wrong elements.
- Extraction: These are the gatherers that appear under the Property column in the Extract action editor.
- Selection Preview: These are the ones that appear under the Selection panel at the bottom.
- Start Processes: This video explains it. It also shows a premade which is probably a better alternative than the Start Processes action.
- Project -> Proxies: Typically you'll get these from a third party proxy vendor. To connect Helium through a proxy, just go to Project -> Proxies, type the address and port (the vendor would give you these), add them to the list and check Enabled. This will connect Helium through the first proxy on the list (you can see the current proxy on Helium's title bar). You may need to authenticate with your vendor's proxy service by visiting any page while the proxy is enabled and fill up the login dialog if it shows up. This won't be needed if they authenticate you by your IP (which is the option I'd recommend). A few actions, such as Repeat and Start Processes have an option to rotate proxies. Every time you rotate proxy, the current proxy is disabled and the next proxy on the list is enabled.
Juan Soldi
The Helium Scraper Team